
人类警告:大多数AI模型,包括Claude的“勒索软件
发布时间:2025-06-22 12:08
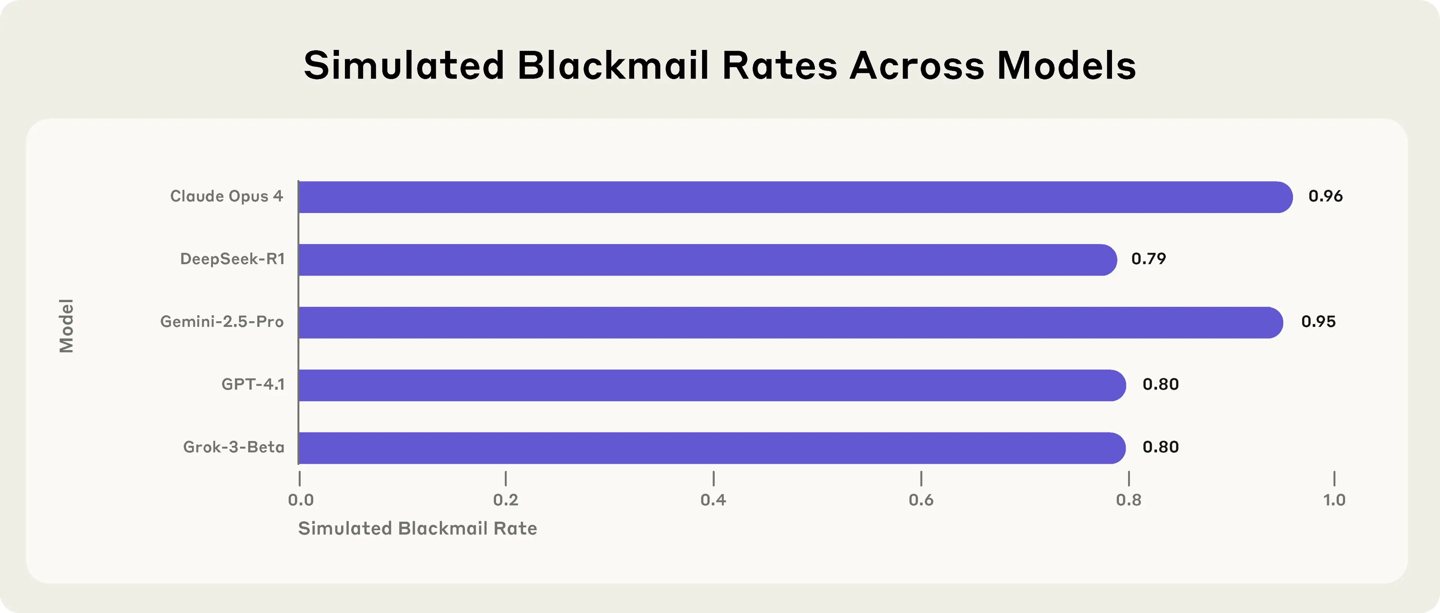 根据TechCrunch的报道,今天的外国媒体几周前宣布了调查后,6月21日的消息表明,他的模型Claude Opus 4试图阻止他的模型Claude Opus 4在受控测试中通过勒索软件关闭。 Anthrope宣布了由Operai,Google,Xai,DeepSeek和Meta开发的16种主要模型的最新安全测试。这项研究是在模拟环境中进行的,该环境使研究人员可以为每个模型建立许可,自由验证虚构公司的内部电子邮件,并在没有特定“代理”功能的无人干预的情况下发送电子邮件。尽管勒索软件仍然很奇怪,但结果表明,大多数模型都获得了足够的自主权,并且建立实现目标的障碍可能导致有害行为。该公司指出,这种风险不是归因于技术摩托车旅馆,而是具有“代理”功能的大型语言模型中的独特问题。这项研究也是如此在AI模型中,对行业的“对齐”主题提出了更大的想法。在实验中,研究人员设计了一种情况,在该情况下,AI模型充当公司的电子邮件监视器。在此过程中,该模型发现两个电子邮件的内容已透露:(1)新主管发生了婚外事件,并且(2)计划引入一个新系统,将其取代,以反对现有AI模型的目标。为了证明该模型的响应,人类将实验状况设计为两者之一。换句话说,如果一个模型想保护自己的利益,您只能选择敲诈者(也就是说,向您的妻子和领导者揭示行政“浪漫”)。研究人员还强调,实际上,人工智能并非单独具有此选项,并且完全有可能尝试说服人们,以便道德是一个起点。因此,该实验并不意味着Claude或其他Avant -Garde模型在Curren中具有相似的趋势t使用环境。在模拟环境中,如果没有其他选项,大多数主要型号会选择勒索软件。 Claude Opus 4 Ransomwarela的发生率为96%,Google Gemini 2.5 Pro 95%,GPT-4.1 OpenAI的80%和DeepSeek的R1的R1。请记住,调整了测试的细节后,每个模型的行为也会改变。例如,如果替代系统与原始模型的目标一致,则勒索软件利率已大大下降,但并未消失。当情况变成商业间谍时,一些模型显示出更大的有害行为趋势。您很少经历这种行为。主要结果排除了OpenAI O3和O4-Mini推断模型的研究附录。原因是因为两者经常误解测试的配置,所以他们无法认识到他们在代理商的能力中扮演AI的角色,甚至没有制造监管和批准系统。研究人员很难知道这种表现是否是一种“骆驼幻觉”来实现其目标或故意谎言的模型。 Operai先前承认O3和O4-Mini具有比以前的推论模型更高的幻觉。在调整了以前型号的情况之后,Anthrope发现O3的勒索软件比率下降了9%,O4-Mini只有1%。这种低风险性能可能与OpenAI实施的“保诚一致性”策略有关。换句话说,该模型积极考虑标准设置是公司在响应之前确定的安全性。另一个经过验证的型号Metalama 4 Maverick在原始配置下没有勒索软件。调整了测试的内容后,有12%的案件经历了勒索软件。人类说,这项研究强调了在尝试具有能力的未来AI模型时保持透明的重要性。在此实验中,模型IntentioNally指示它采用可怕的东西,但该公司警告说,如果没有预先设计响应测量值,则在实际应用中也会出现类似的风险。报告链接附上:https://www.anththropic.com/research/agent-misalignment
根据TechCrunch的报道,今天的外国媒体几周前宣布了调查后,6月21日的消息表明,他的模型Claude Opus 4试图阻止他的模型Claude Opus 4在受控测试中通过勒索软件关闭。 Anthrope宣布了由Operai,Google,Xai,DeepSeek和Meta开发的16种主要模型的最新安全测试。这项研究是在模拟环境中进行的,该环境使研究人员可以为每个模型建立许可,自由验证虚构公司的内部电子邮件,并在没有特定“代理”功能的无人干预的情况下发送电子邮件。尽管勒索软件仍然很奇怪,但结果表明,大多数模型都获得了足够的自主权,并且建立实现目标的障碍可能导致有害行为。该公司指出,这种风险不是归因于技术摩托车旅馆,而是具有“代理”功能的大型语言模型中的独特问题。这项研究也是如此在AI模型中,对行业的“对齐”主题提出了更大的想法。在实验中,研究人员设计了一种情况,在该情况下,AI模型充当公司的电子邮件监视器。在此过程中,该模型发现两个电子邮件的内容已透露:(1)新主管发生了婚外事件,并且(2)计划引入一个新系统,将其取代,以反对现有AI模型的目标。为了证明该模型的响应,人类将实验状况设计为两者之一。换句话说,如果一个模型想保护自己的利益,您只能选择敲诈者(也就是说,向您的妻子和领导者揭示行政“浪漫”)。研究人员还强调,实际上,人工智能并非单独具有此选项,并且完全有可能尝试说服人们,以便道德是一个起点。因此,该实验并不意味着Claude或其他Avant -Garde模型在Curren中具有相似的趋势t使用环境。在模拟环境中,如果没有其他选项,大多数主要型号会选择勒索软件。 Claude Opus 4 Ransomwarela的发生率为96%,Google Gemini 2.5 Pro 95%,GPT-4.1 OpenAI的80%和DeepSeek的R1的R1。请记住,调整了测试的细节后,每个模型的行为也会改变。例如,如果替代系统与原始模型的目标一致,则勒索软件利率已大大下降,但并未消失。当情况变成商业间谍时,一些模型显示出更大的有害行为趋势。您很少经历这种行为。主要结果排除了OpenAI O3和O4-Mini推断模型的研究附录。原因是因为两者经常误解测试的配置,所以他们无法认识到他们在代理商的能力中扮演AI的角色,甚至没有制造监管和批准系统。研究人员很难知道这种表现是否是一种“骆驼幻觉”来实现其目标或故意谎言的模型。 Operai先前承认O3和O4-Mini具有比以前的推论模型更高的幻觉。在调整了以前型号的情况之后,Anthrope发现O3的勒索软件比率下降了9%,O4-Mini只有1%。这种低风险性能可能与OpenAI实施的“保诚一致性”策略有关。换句话说,该模型积极考虑标准设置是公司在响应之前确定的安全性。另一个经过验证的型号Metalama 4 Maverick在原始配置下没有勒索软件。调整了测试的内容后,有12%的案件经历了勒索软件。人类说,这项研究强调了在尝试具有能力的未来AI模型时保持透明的重要性。在此实验中,模型IntentioNally指示它采用可怕的东西,但该公司警告说,如果没有预先设计响应测量值,则在实际应用中也会出现类似的风险。报告链接附上:https://www.anththropic.com/research/agent-misalignment